As demand for real-world behavioral data surges alongside Robotics AI and Embodied AI, decentralized data networks are emerging as a critical pillar of AI infrastructure.
Caspius and traditional AI data platforms both serve to collect AI training data, making them frequent subjects of comparison. While both support AI model training, they differ fundamentally in data control, value distribution logic, and ecosystem architecture.
What Is Caspius?
Caspius is a data infrastructure protocol tailored for Robotics AI and Embodied AI. It gathers real-world behavioral data through an open network, supplying raw material for AI model training.
The project zeroes in on first-person video, motion trajectories, and environment interaction data needed for robot training. This data enables robotic systems to master real-world action execution, spatial reasoning, and physical feedback.
Unlike traditional platforms, Caspius leverages blockchain incentive mechanisms, allowing everyday users to contribute data. By uploading valid training data, users earn rewards in CAS tokens.
From a positioning perspective, Caspius aligns more closely with open AI data networks and DePIN infrastructure projects.
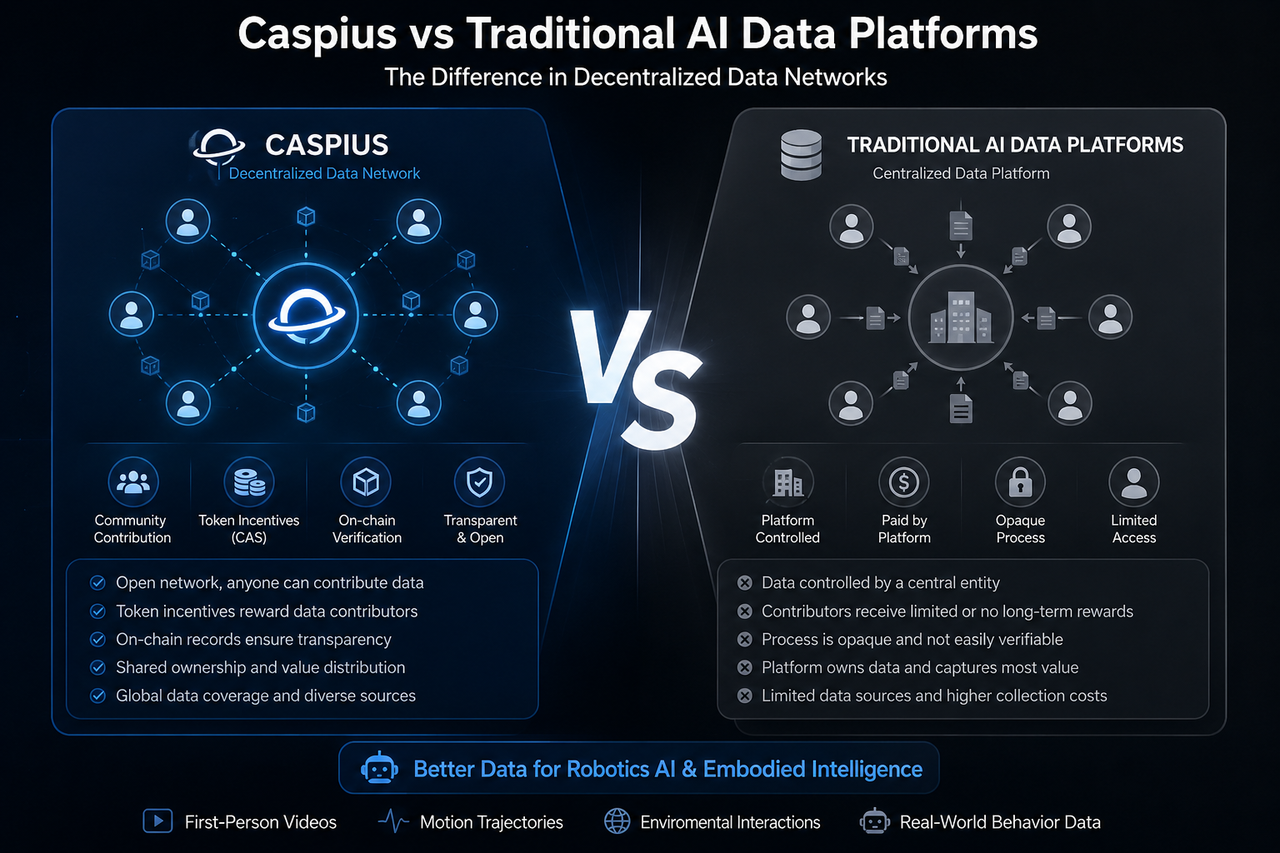
Traditional AI data platforms are typically run by centralized enterprises that handle data collection, annotation, organization, and sales.
In the conventional model, the platform standardizes the data collection workflow. Annotation teams then classify and process the data, ultimately offering training data services to AI companies. Today, many large language models, image recognition systems, and autonomous driving models rely on data from these platforms.
This approach has been standard in the AI industry for years, prized for its operational efficiency and mature data validation processes. However, control over data and revenue distribution tends to remain concentrated within the platform.
Data ownership marks one of the key distinctions between Caspius and traditional AI data platforms.
Traditional platforms generally follow a centralized model: they collect, store, and monetize data, leaving contributors with little to no role in ongoing value distribution.
Caspius, by contrast, emphasizes open collaboration and on-chain incentive logic. In theory, data contributors can not only upload training data but also participate in ecosystem value flows via the token mechanism.
The following table highlights the structural differences in data:
| Comparison Aspect |
Caspius |
Traditional AI Data Platforms |
| Data Control Method |
Open network |
Centralized platform control |
| Data Contribution Model |
Community collaboration |
Enterprise collection |
| Revenue Distribution |
On-chain incentive mechanism |
Platform-led |
| Data Transparency |
Verifiable mechanism |
Opaque processes |
| Network Structure |
Decentralized |
Centralized |
These differences position Caspius closer to the Web3 data economy.
Traditional AI data platforms usually operate on a fixed payment model. For instance, they pay data collectors or annotation teams and then sell the processed data to AI companies.
Caspius, on the other hand, uses token incentives to scale data supply. Users who upload valid training data receive CAS tokens, and the network attracts more contributors through economic rewards.
The core advantage of this model is open participation. Unlike traditional platforms that rely on enterprise-managed data collection, Caspius prioritizes community collaboration and globally sourced data.
That said, the token incentive model can be affected by market cycles, token price volatility, and ecosystem development pace, so its long-term viability remains to be seen.
Traditional AI data platforms typically operate as closed systems, making it hard for outsiders to trace data origins, filtering criteria, or audit standards.
Caspius aims to boost transparency through on-chain mechanisms. For example, certain data processes may include on-chain records, verifiable contributions, and community audits, enhancing open collaboration.
Transparency is growing in importance for AI data networks. As AI models scale up, the market is paying closer attention to training data provenance and quality control.
However, for robot training data, on-chain records alone are rarely sufficient to guarantee quality, making robust data validation mechanisms essential.
What Challenges Does Caspius Face?
Despite the growth potential of decentralized AI data networks, Caspius must overcome several hurdles.
First is authenticity. Robot training data demands high precision; low-quality or fake data can derail model training. Robust verification is therefore critical.
Second are privacy and regulatory concerns. Real-world video and behavioral data may involve user privacy, geolocation, and varying regional regulations.
Moreover, large AI companies already possess strong in-house data collection capabilities. Whether open data networks can sustain a competitive advantage in the long run remains to be tested.
As a crypto asset, CAS's market performance is also subject to industry cycles and market fluctuations.
Conclusion
While both Caspius and traditional AI data platforms support AI model training, they diverge markedly in data network structure, value distribution logic, and ecosystem design.
Traditional platforms rely on centralized management, whereas Caspius champions open collaboration, community contribution, and on-chain incentives. With the rapid growth of Robotics AI and Embodied AI, the need for real-world training data is escalating, and decentralized data networks are becoming a key component of AI infrastructure.
Nevertheless, the AI data market is still evolving rapidly. Issues around data quality, regulatory compliance, and ecosystem sustainability will continue to shape the industry's long-term trajectory.
FAQs
What are traditional AI data platforms?
Traditional AI data platforms are typically operated by centralized enterprises responsible for data collection, annotation, management, and commercial distribution.
What is the biggest difference between Caspius and traditional AI data platforms?
The main difference lies in data network structure. Caspius emphasizes open collaboration and on-chain incentives, while traditional platforms rely on centralized management.
Why does robotics AI need so much real-world data?
Robotic systems must learn action execution, spatial relationships, and environmental interaction. Text data alone is insufficient for complex behavior training.
What are the risks of decentralized AI data networks?
Decentralized data networks may face challenges related to data authenticity, privacy compliance, data quality, and ecosystem sustainability.








