rickawsb
用戶暫無簡介
rickawsb
AI的盡頭是光刻機,光刻機的盡頭是鏡頭
--- 光刻機鏡頭為何困難?
EUV和高端DUV光學,是整個超精密工業體系的極限集合。它同時依賴材料、鍍膜、計量、裝調、熱控制、振動控制、算法、誤差建模和長期經驗積累。真正限制擴產的,往往不是單一零件,而是整個“精度閉環”。
這個閉環裡最核心是:你無法製造出比自己測量能力更精確的東西。
EUV的13.5nm波長幾乎會被所有材料吸收,所以EUV根本不能使用傳統透鏡,只能使用多層反射鏡。蔡司的EUV鏡面,本質上是一套原子級反射系統。鏡面表面誤差通常要求進入幾十皮米級別。
1 pm=10−12 米
原子直徑大約100pm,意味著很多EUV鏡面的允許誤差已經接近半個原子層。
比做這樣一面鏡子更難的,是如何穩定測量這種誤差。如何在熱漂移、空氣擾動、振動下完成測量。如何在大尺寸鏡面上保持一致性。如何形成長期穩定的工業化重複製造。因為這時候測量的已經不是長度,而是光波相位本身。
EUV測量系統本身,就是一套超高端產業鏈。裡面包括激光干涉儀、超穩定激光源、reference optics(參考鏡)、超低熱膨脹材料、主動隔振系統、超精密位移台、波前傳感器、真空系統和長期漂移補償算法。很多核心供應商,全球可能只有1-3家。
而這些計量系統也需要更高等級的計量系統來製造。於是形成一種遞歸(死循環):先進的計量設備製造需要更先進的計量設備。
以其中瓶頸之一,refe
查看原文--- 光刻機鏡頭為何困難?
EUV和高端DUV光學,是整個超精密工業體系的極限集合。它同時依賴材料、鍍膜、計量、裝調、熱控制、振動控制、算法、誤差建模和長期經驗積累。真正限制擴產的,往往不是單一零件,而是整個“精度閉環”。
這個閉環裡最核心是:你無法製造出比自己測量能力更精確的東西。
EUV的13.5nm波長幾乎會被所有材料吸收,所以EUV根本不能使用傳統透鏡,只能使用多層反射鏡。蔡司的EUV鏡面,本質上是一套原子級反射系統。鏡面表面誤差通常要求進入幾十皮米級別。
1 pm=10−12 米
原子直徑大約100pm,意味著很多EUV鏡面的允許誤差已經接近半個原子層。
比做這樣一面鏡子更難的,是如何穩定測量這種誤差。如何在熱漂移、空氣擾動、振動下完成測量。如何在大尺寸鏡面上保持一致性。如何形成長期穩定的工業化重複製造。因為這時候測量的已經不是長度,而是光波相位本身。
EUV測量系統本身,就是一套超高端產業鏈。裡面包括激光干涉儀、超穩定激光源、reference optics(參考鏡)、超低熱膨脹材料、主動隔振系統、超精密位移台、波前傳感器、真空系統和長期漂移補償算法。很多核心供應商,全球可能只有1-3家。
而這些計量系統也需要更高等級的計量系統來製造。於是形成一種遞歸(死循環):先進的計量設備製造需要更先進的計量設備。
以其中瓶頸之一,refe

- 打賞
- 按讚
- 回覆
- 轉發
- 分享
加倉了儲存,光
希望不會抄底抄在半山腰😅
查看原文希望不會抄底抄在半山腰😅
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
周末行研---AI拉動的電力電子系統大基建裡SiC、GaN 與硅MOSFET的份額淺析
AI數據中心瘋狂建設推動的電網大升級,正在讓另一個長期被低估的領域重新回到舞台中央:功率半導體。
電力系統核心在於高效地控制電流。而控制電流最核心的器件,就是MOSFET(Metal-Oxide-Semiconductor Field-Effect Transistor)金屬-氧化物-半導體場效應晶體管。
過去幾十年,全球功率器件幾乎都建立在硅MOSFET之上。硅便宜、成熟、產業鏈完整,因此長期統治整個行業。但隨著AI伺服器功率暴漲、EV進入800V時代、數據中心向高壓化演進、高頻電源需求提升,傳統硅開始逐漸碰到物理極限。於是,SiC(碳化硅)與GaN(氮化鎵)開始崛起。
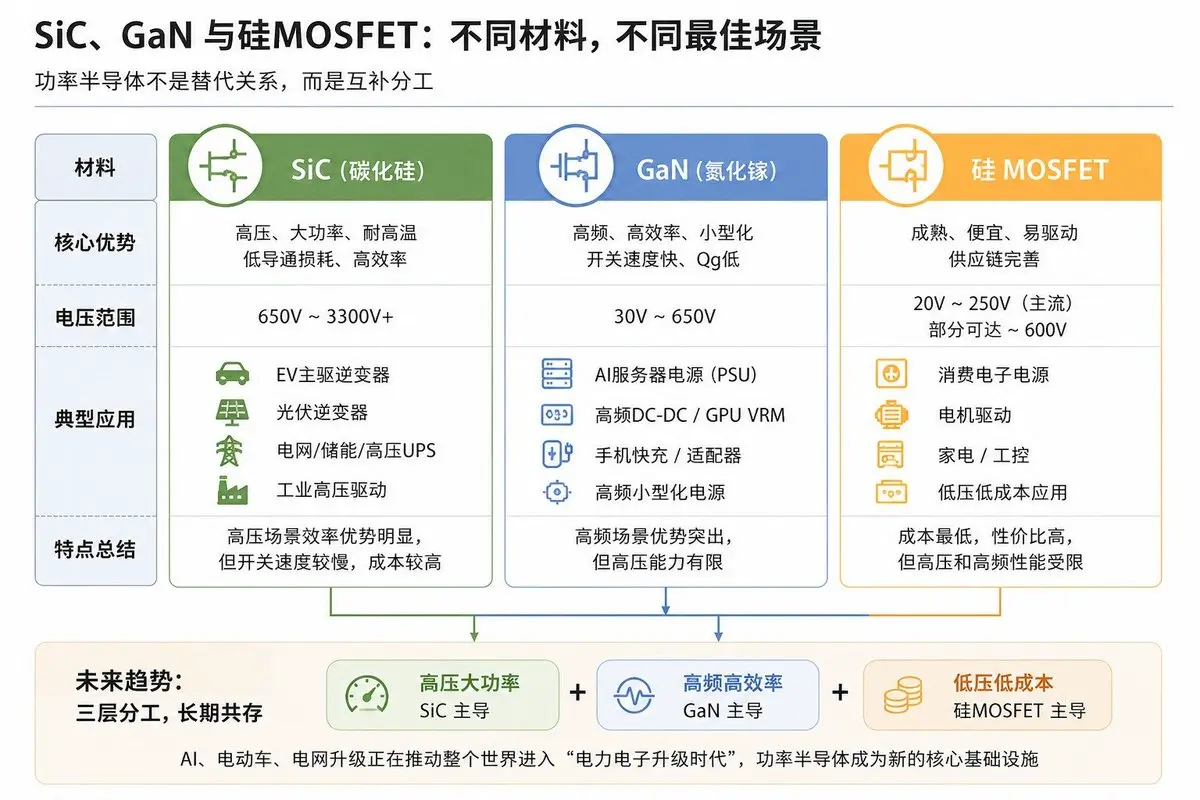
SiC更像重工業路線。它的核心優勢,在於高壓與大功率。SiC擁有更高擊穿電壓、更強導熱能力,在高壓、高電流場景下效率明顯優於傳統硅IGBT。因此EV主驅逆變器、光伏逆變器、儲能、工業高壓驅動、電網、高壓UPS這些領域,正在快速SiC化。尤其特斯拉推動的800V平台,本質上是整個SiC產業爆發的重要轉折點。過去幾年,新能源車一直是SiC最大的驅動力。Wolfspeed、onsemi、STMicroelectronics、Infineon Technologies、ROHM、Mitsubishi Electric等
查看原文AI數據中心瘋狂建設推動的電網大升級,正在讓另一個長期被低估的領域重新回到舞台中央:功率半導體。
電力系統核心在於高效地控制電流。而控制電流最核心的器件,就是MOSFET(Metal-Oxide-Semiconductor Field-Effect Transistor)金屬-氧化物-半導體場效應晶體管。
過去幾十年,全球功率器件幾乎都建立在硅MOSFET之上。硅便宜、成熟、產業鏈完整,因此長期統治整個行業。但隨著AI伺服器功率暴漲、EV進入800V時代、數據中心向高壓化演進、高頻電源需求提升,傳統硅開始逐漸碰到物理極限。於是,SiC(碳化硅)與GaN(氮化鎵)開始崛起。
SiC更像重工業路線。它的核心優勢,在於高壓與大功率。SiC擁有更高擊穿電壓、更強導熱能力,在高壓、高電流場景下效率明顯優於傳統硅IGBT。因此EV主驅逆變器、光伏逆變器、儲能、工業高壓驅動、電網、高壓UPS這些領域,正在快速SiC化。尤其特斯拉推動的800V平台,本質上是整個SiC產業爆發的重要轉折點。過去幾年,新能源車一直是SiC最大的驅動力。Wolfspeed、onsemi、STMicroelectronics、Infineon Technologies、ROHM、Mitsubishi Electric等
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
KPMG 美國 AI Pulse 系列顯示,大型企業 AI 投資預期在 2026 年初明顯加速。
平均預計 AI 支出從 2025 年第一季度約 1.14 億美元,升至 2025 年第三季度 1.30 億美元,2025 年第四季度為 1.24 億美元,再到 2026 年第一季度 2.07 億美元。
這是大型企業群體的指標,而大型企業正是 hyperscaler 服務的主要消費方。
查看原文平均預計 AI 支出從 2025 年第一季度約 1.14 億美元,升至 2025 年第三季度 1.30 億美元,2025 年第四季度為 1.24 億美元,再到 2026 年第一季度 2.07 億美元。
這是大型企業群體的指標,而大型企業正是 hyperscaler 服務的主要消費方。
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
hyperscaler的aidc資本支出今年已經超過美國軍費
而智能是終極的軍事能力…
查看原文而智能是終極的軍事能力…
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
做空的老師們,你們要保重啊
千萬慢點虧
你們要是虧光離場了,美股就只剩赤裸裸的賺錢
我們這些多頭就會少了很多過程中的樂趣🤣
查看原文千萬慢點虧
你們要是虧光離場了,美股就只剩赤裸裸的賺錢
我們這些多頭就會少了很多過程中的樂趣🤣
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
幣圈玩家基本好像都退圈了?
很多大V開始炒美股了?
幣圈機會來了,一些非常切合趨勢的標的,現在盈虧比其實相當高
iykyk
查看原文很多大V開始炒美股了?
幣圈機會來了,一些非常切合趨勢的標的,現在盈虧比其實相當高
iykyk
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
財報前瞻:
明天是美股的大日子,微軟Google亞馬遜Meta四大科技公司財報。這是AI板塊的moment of truth 時刻
這輪大科技財報,核心只看一件事:AI投入,是否已經開始轉化為可解釋CapEx的現金流,且在快速增長。
財報恰逢美股回調,最近這波回調,本質就是漲多了,美股已經歷史性的18連漲;指數高度集中,權重股波動被放大;預期已經被相對充分消化,任何新增變數都會觸發獲利了結。
但AI需求很強,而且還在加速,主要來自頭部AI公司、大科技自身以及部分高價值客戶;供給受GPU、电力、數據中心等物理約束,擴張明顯滯後;供需缺口巨大,而且仍在繼續擴大。
高端算力持續緊張,資源向高價值客戶集中,AI相關收入能力在提升。
但市場已經多少了解這些信息,真正要看的,是需求能不能持續穿透供給約束,轉化為收入,再轉化為現金流。
判斷需要基於三點
第一,收入有沒有持續兌現,看雲業務、AI收入、usage增長;
第二,增長有沒有加速,看客戶數、調用量、單位價值是否在提升;
第三,現金流有沒有進入上升通道,而且斜率是否在變陡,這是最關鍵的一點。
這些是目前對市場來說,比CapEx重要的多的指標。
因為只有現金流增長,才能支持CapEx繼續增長,才是正循環。反之市場又會陷入支出恐懼,參考昨天的amkr財報後股價表現。
免責聲明:本人持有文中提及的標的,觀點必然偏頗,文章內容非投資建議,股票投資風
查看原文明天是美股的大日子,微軟Google亞馬遜Meta四大科技公司財報。這是AI板塊的moment of truth 時刻
這輪大科技財報,核心只看一件事:AI投入,是否已經開始轉化為可解釋CapEx的現金流,且在快速增長。
財報恰逢美股回調,最近這波回調,本質就是漲多了,美股已經歷史性的18連漲;指數高度集中,權重股波動被放大;預期已經被相對充分消化,任何新增變數都會觸發獲利了結。
但AI需求很強,而且還在加速,主要來自頭部AI公司、大科技自身以及部分高價值客戶;供給受GPU、电力、數據中心等物理約束,擴張明顯滯後;供需缺口巨大,而且仍在繼續擴大。
高端算力持續緊張,資源向高價值客戶集中,AI相關收入能力在提升。
但市場已經多少了解這些信息,真正要看的,是需求能不能持續穿透供給約束,轉化為收入,再轉化為現金流。
判斷需要基於三點
第一,收入有沒有持續兌現,看雲業務、AI收入、usage增長;
第二,增長有沒有加速,看客戶數、調用量、單位價值是否在提升;
第三,現金流有沒有進入上升通道,而且斜率是否在變陡,這是最關鍵的一點。
這些是目前對市場來說,比CapEx重要的多的指標。
因為只有現金流增長,才能支持CapEx繼續增長,才是正循環。反之市場又會陷入支出恐懼,參考昨天的amkr財報後股價表現。
免責聲明:本人持有文中提及的標的,觀點必然偏頗,文章內容非投資建議,股票投資風
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
今天 Amkor Technology 財報是一份大超預期的財報。
營收達到16.9億美元,同比大幅增長,並明顯高於市場一致預期;EPS同樣大幅超出預期,背後是產能利用率從此前低位快速回升到70%區間。更關鍵的是,公司給出的下一季度指引繼續大幅上修。
但市場卻毫不給面子,盤後股價一度跌幅達8%。
到底哪裡出了問題?
硬要找,只有一個:公司將全年資本開支從過去約7.5億美元直接提高到25-30億美元,增幅接近3倍。
這看起來像是之前市場對大科技的capex大幅增長,現金流擔憂的復現。
但這個顧慮到底有沒有道理?
要解答這個問題,需要先把先進封裝這件事拆開來看。
本質上,封裝在回答一個問題:算力如何被高效地“物理實現”。
圍繞這個問題,產業鏈形成了清晰分工:TSMC負責前道製造,把電路刻進矽裡;Amkor負責後道封裝測試,把裸晶片變成可用芯片。从歷史上看,兩者幾乎沒有重疊。但在AI時代,封裝開始直接影響帶寬、功耗與系統性能,先進封裝逐漸“前道化”,tsmc開始用cowos和amkr競爭,邊界開始模糊,不過這種變化主要集中在最頂端的一小段。
Amkor的技術路徑恰好位於另一側。它的先進封裝重心在Fan-Out體系,其中HDFO(高密度Fan-Out)是當前最關鍵的增長抓手,同時也在布局2.5D和3D。
CoWoS由TSMC主導,基於矽中介層(interposer),服務HBM與AI G
查看原文營收達到16.9億美元,同比大幅增長,並明顯高於市場一致預期;EPS同樣大幅超出預期,背後是產能利用率從此前低位快速回升到70%區間。更關鍵的是,公司給出的下一季度指引繼續大幅上修。
但市場卻毫不給面子,盤後股價一度跌幅達8%。
到底哪裡出了問題?
硬要找,只有一個:公司將全年資本開支從過去約7.5億美元直接提高到25-30億美元,增幅接近3倍。
這看起來像是之前市場對大科技的capex大幅增長,現金流擔憂的復現。
但這個顧慮到底有沒有道理?
要解答這個問題,需要先把先進封裝這件事拆開來看。
本質上,封裝在回答一個問題:算力如何被高效地“物理實現”。
圍繞這個問題,產業鏈形成了清晰分工:TSMC負責前道製造,把電路刻進矽裡;Amkor負責後道封裝測試,把裸晶片變成可用芯片。从歷史上看,兩者幾乎沒有重疊。但在AI時代,封裝開始直接影響帶寬、功耗與系統性能,先進封裝逐漸“前道化”,tsmc開始用cowos和amkr競爭,邊界開始模糊,不過這種變化主要集中在最頂端的一小段。
Amkor的技術路徑恰好位於另一側。它的先進封裝重心在Fan-Out體系,其中HDFO(高密度Fan-Out)是當前最關鍵的增長抓手,同時也在布局2.5D和3D。
CoWoS由TSMC主導,基於矽中介層(interposer),服務HBM與AI G
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
財報速覽:Rambus (RMBS)
Rambus 股價在財報後跌超 10%,核心數據顯示:AI 存儲市場正處於從規模擴張向技術代差驅動的轉型期。
核心財務邏輯:增收不增利背後的“軍備競賽”
Rambus Q1 營收 1.802 億美元,同比增長 8%。關鍵亮點在於產品營收(晶片)同比增長 15%,這抵消了授權業務的疲軟。
現狀: 市場對物理晶片(如 DDR5 接口晶片)的剛需遠超專利授權。
代價: 為了保住技術領先,研發投入大幅攀升,導致營運利潤率從 38% 壓縮至 34%。這是典型的“拿利潤換未來”的半導體競賽階段。
需求側的移位:推理與智能體(Agentic AI)
財報中 CEO 提到的關鍵詞是 “Agentic workloads”。這標誌著 AI 需求已發生結構性變化:
從“訓練”到“部署”: 早期增長靠買 GPU 練模型,現在的增長靠成千上萬的 AI 智能體線上運行。
帶寬即生命: 推理和智能體任務需要極高的數據交換頻率,存儲不再只是“倉庫”,而是“高速公路”。
技術迭代的“深水區”:HBM4E 與 SOCAMM2
Rambus 的技術路線圖目標是 AI 數據中心的兩大痛點:
速度瓶頸: HBM4E 記憶控制器 IP 預示著下一代 AI 顯存標準的到來,帶寬競爭沒有上限。
電力瓶頸: LPDDR5X SOCAMM2 模組將移動端的低功耗特性引入伺服器。在電力受限的當下
查看原文Rambus 股價在財報後跌超 10%,核心數據顯示:AI 存儲市場正處於從規模擴張向技術代差驅動的轉型期。
核心財務邏輯:增收不增利背後的“軍備競賽”
Rambus Q1 營收 1.802 億美元,同比增長 8%。關鍵亮點在於產品營收(晶片)同比增長 15%,這抵消了授權業務的疲軟。
現狀: 市場對物理晶片(如 DDR5 接口晶片)的剛需遠超專利授權。
代價: 為了保住技術領先,研發投入大幅攀升,導致營運利潤率從 38% 壓縮至 34%。這是典型的“拿利潤換未來”的半導體競賽階段。
需求側的移位:推理與智能體(Agentic AI)
財報中 CEO 提到的關鍵詞是 “Agentic workloads”。這標誌著 AI 需求已發生結構性變化:
從“訓練”到“部署”: 早期增長靠買 GPU 練模型,現在的增長靠成千上萬的 AI 智能體線上運行。
帶寬即生命: 推理和智能體任務需要極高的數據交換頻率,存儲不再只是“倉庫”,而是“高速公路”。
技術迭代的“深水區”:HBM4E 與 SOCAMM2
Rambus 的技術路線圖目標是 AI 數據中心的兩大痛點:
速度瓶頸: HBM4E 記憶控制器 IP 預示著下一代 AI 顯存標準的到來,帶寬競爭沒有上限。
電力瓶頸: LPDDR5X SOCAMM2 模組將移動端的低功耗特性引入伺服器。在電力受限的當下
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
半導體產業鏈之上,數字孿生之前:良率提升的隱形冠軍分析
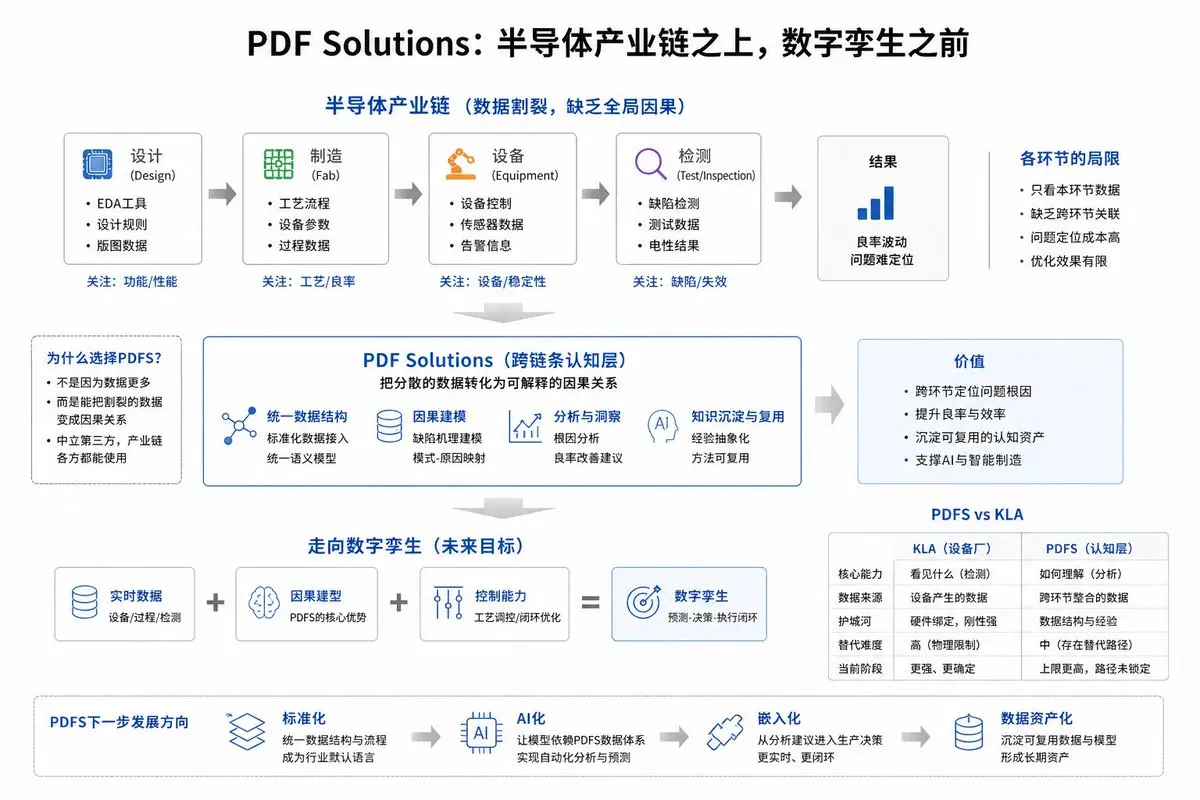
如果把半導體製造當成一個系統來看會發現一個被長期忽視的位置:在產業鏈之上、在數字孿生真正落地之前,存在一層尚未被完全定義的跨企業,全流程的“認知層”。PDF Solutions的價值,就來自這裡。
它處理的不是單點數據,而是貫穿設計、工藝、設備、測試的因果鏈:某個設計結構,在某個工藝步驟、某台設備上形成特定缺陷,最終映射為電性失效。單個晶圓廠或者檢測機構可以擁有某些環節的全部原始數據,但很難把這些數據穩定地連接成可重用的因果模型,這就是PDFS切入的本質。
為什麼EDA、晶圓廠、設備廠沒有把這件事自己做完?不是做不到,而是沒有動力做到那一步。
設計端如Synopsys、Cadence Design Systems只能做到前馈優化,缺乏製造後的反饋閉環;
晶圓廠如TSMC、Intel數據最全,但系統割裂、組織分散,跨流程整合成本極高;
設備廠如KLA Corporation、Applied Materials掌握檢測和控制,但視角局限在單工序。
每一層都在優化局部,跨邊界問題無人承接,于是在產業鏈之上,自然出現了一層“解釋系統”的空白,這正是PDFS所在的位置。
產業鏈使用PDFS,是因為數據之間的斷層——設計看設計,工藝看工藝,設備看缺陷,但沒有統一機制把這些信息串成一條可解釋的因果鏈。PDFS
查看原文如果把半導體製造當成一個系統來看會發現一個被長期忽視的位置:在產業鏈之上、在數字孿生真正落地之前,存在一層尚未被完全定義的跨企業,全流程的“認知層”。PDF Solutions的價值,就來自這裡。
它處理的不是單點數據,而是貫穿設計、工藝、設備、測試的因果鏈:某個設計結構,在某個工藝步驟、某台設備上形成特定缺陷,最終映射為電性失效。單個晶圓廠或者檢測機構可以擁有某些環節的全部原始數據,但很難把這些數據穩定地連接成可重用的因果模型,這就是PDFS切入的本質。
為什麼EDA、晶圓廠、設備廠沒有把這件事自己做完?不是做不到,而是沒有動力做到那一步。
設計端如Synopsys、Cadence Design Systems只能做到前馈優化,缺乏製造後的反饋閉環;
晶圓廠如TSMC、Intel數據最全,但系統割裂、組織分散,跨流程整合成本極高;
設備廠如KLA Corporation、Applied Materials掌握檢測和控制,但視角局限在單工序。
每一層都在優化局部,跨邊界問題無人承接,于是在產業鏈之上,自然出現了一層“解釋系統”的空白,這正是PDFS所在的位置。
產業鏈使用PDFS,是因為數據之間的斷層——設計看設計,工藝看工藝,設備看缺陷,但沒有統一機制把這些信息串成一條可解釋的因果鏈。PDFS
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
美股現在是徹底進入山寨季了嗎?
這劇本我熟啊🤣
查看原文這劇本我熟啊🤣
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
最近提交IPO的AI芯片新宠Cerebras火遍硅谷。
其芯片在小模型场景下,其推理速度最高可达H100的20倍;而超大规模模型(如400B参数量级),Cerebras CS-3系统的单用户响应速度约为B200的2.4倍
那么Cerebras究竟是如何做到的呢?它是否会成为英伟达杀手呢?
我们需从算力演进的本质开始。
AI算力的演进,正在从“算力本身”转向“通信与系统结构”。在这条演进路径上,Cerebras Systems提供了一种完全不同的答案:不是优化分布式,而是尽可能消灭分布式。
一、两条路线:消灭通信 vs 优化通信
当前AI算力本质上分为两种架构哲学:一条是以NVIDIA为代表的路线:
多芯片(GPU),高速互连(NVLink / CPO),scale-out(横向扩展)
另一条是Cerebras路径:单芯片做到极限(wafer-scale)
片内网络替代跨节点通信,scale-up(纵向放大)
核心区别是:一条在解决“如何连接更多芯片”,另一条在解决“如何不需要连接”。
二、为什么这条路现在才成立
wafer-scale并不是新概念,80年代就有人尝试,90年代商业化失败。原因是:
良率无法承受
没有容错机制
软件无法支撑
行业因此形成共识:小die + 高良率 + 分布式。
Cerebras的突破在于三件事同时成立:
1)容错机制工程化
2)片上网络成熟
3)AI
查看原文其芯片在小模型场景下,其推理速度最高可达H100的20倍;而超大规模模型(如400B参数量级),Cerebras CS-3系统的单用户响应速度约为B200的2.4倍
那么Cerebras究竟是如何做到的呢?它是否会成为英伟达杀手呢?
我们需从算力演进的本质开始。
AI算力的演进,正在从“算力本身”转向“通信与系统结构”。在这条演进路径上,Cerebras Systems提供了一种完全不同的答案:不是优化分布式,而是尽可能消灭分布式。
一、两条路线:消灭通信 vs 优化通信
当前AI算力本质上分为两种架构哲学:一条是以NVIDIA为代表的路线:
多芯片(GPU),高速互连(NVLink / CPO),scale-out(横向扩展)
另一条是Cerebras路径:单芯片做到极限(wafer-scale)
片内网络替代跨节点通信,scale-up(纵向放大)
核心区别是:一条在解决“如何连接更多芯片”,另一条在解决“如何不需要连接”。
二、为什么这条路现在才成立
wafer-scale并不是新概念,80年代就有人尝试,90年代商业化失败。原因是:
良率无法承受
没有容错机制
软件无法支撑
行业因此形成共识:小die + 高良率 + 分布式。
Cerebras的突破在于三件事同时成立:
1)容错机制工程化
2)片上网络成熟
3)AI

- 打賞
- 按讚
- 回覆
- 轉發
- 分享
周末深度:從CPO + ELS光源趨勢看獨立激光器玩家的位置、邊界與終局
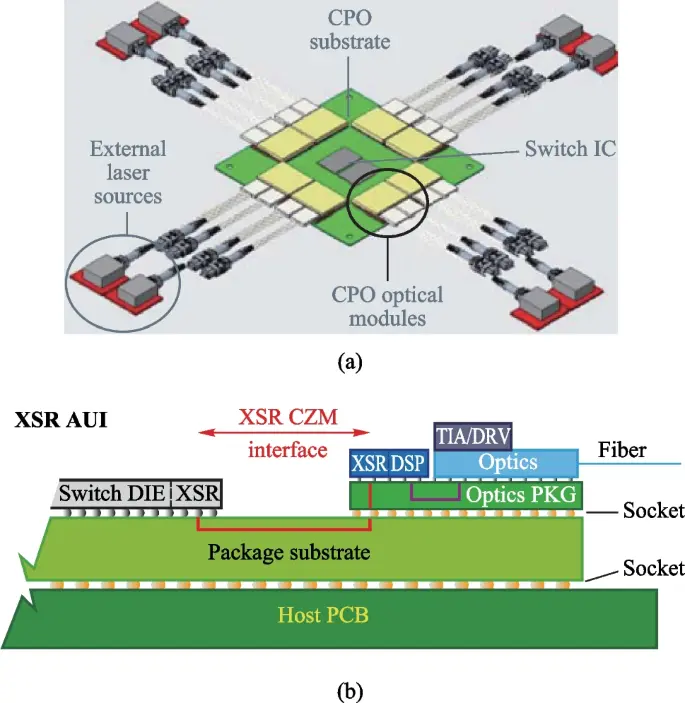
AI算力的瓶頸正在從計算轉向帶寬。隨著GPU規模擴大,節點間通信接近N²增長,電互連在功耗與距離上觸頂,光互連從“可選項”變成“剛需”。
在這一過程中,CPO(Co-Packaged Optics)與ELS(External Laser Source)開始重構產業鏈:激光器從模組內部被剝離,成為系統級資源。
獨立激光器玩家SIVEF正處在這個變化的一個關鍵節點。
一、SIVEF做什麼
公司核心是基於InP平台的WDM DFB激光陣列。
簡單說:
DFB:穩定單波長激光器
WDM:多波長復用
array:多激光器一體化
本質不是賣“激光器”,而是提供多通道光帶寬能力。
在CPO + ELS架構下:
傳統:每個模組一個激光器
新架構:一個光源供多個通道
激光器從“分佈式元件”變成“集中資源”,這就是價值重分配的起點。
二、為什麼是WDM DFB array
AI數據中心的約束很清晰:單通道速率接近極限,電互連功耗不可擴展,帶寬必須靠“並行化”
唯一可擴展路徑是:
多波長(WDM)
而WDM的前提是:穩定、可控的單波長光源(DFB)
因此,WDM DFB array是當前工程上最優解。儘管不是最先進的理論方案,但它是唯一可規模化落地的方
查看原文AI算力的瓶頸正在從計算轉向帶寬。隨著GPU規模擴大,節點間通信接近N²增長,電互連在功耗與距離上觸頂,光互連從“可選項”變成“剛需”。
在這一過程中,CPO(Co-Packaged Optics)與ELS(External Laser Source)開始重構產業鏈:激光器從模組內部被剝離,成為系統級資源。
獨立激光器玩家SIVEF正處在這個變化的一個關鍵節點。
一、SIVEF做什麼
公司核心是基於InP平台的WDM DFB激光陣列。
簡單說:
DFB:穩定單波長激光器
WDM:多波長復用
array:多激光器一體化
本質不是賣“激光器”,而是提供多通道光帶寬能力。
在CPO + ELS架構下:
傳統:每個模組一個激光器
新架構:一個光源供多個通道
激光器從“分佈式元件”變成“集中資源”,這就是價值重分配的起點。
二、為什麼是WDM DFB array
AI數據中心的約束很清晰:單通道速率接近極限,電互連功耗不可擴展,帶寬必須靠“並行化”
唯一可擴展路徑是:
多波長(WDM)
而WDM的前提是:穩定、可控的單波長光源(DFB)
因此,WDM DFB array是當前工程上最優解。儘管不是最先進的理論方案,但它是唯一可規模化落地的方
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
看了一下,現在不少美股知名大V喊單的小票,純敘事啊
我的一階思維:價值投資,賭博不參與
我的二階思維:作為幣圈土狗玩家,必須無腦梭哈🤣
查看原文我的一階思維:價值投資,賭博不參與
我的二階思維:作為幣圈土狗玩家,必須無腦梭哈🤣
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
moonshots頻道今天一個觀點:
ai會讓科斯定律失效
醍醐灌頂!
組織的存在,最重要原因之一是因為組織內協調成本低於市場交易成本
當ai讓交易成本降幅遠超組織成本降幅的時候,組織存在的意義就大大降低了
對公司來說是這樣,對國家來說也是。
查看原文ai會讓科斯定律失效
醍醐灌頂!
組織的存在,最重要原因之一是因為組織內協調成本低於市場交易成本
當ai讓交易成本降幅遠超組織成本降幅的時候,組織存在的意義就大大降低了
對公司來說是這樣,對國家來說也是。
- 打賞
- 1
- 1
- 轉發
- 分享
ybaser:
就這樣勇往直前 👊就這樣勇往直前 👊所有知識(腦力)工作者,都会被ai取代
包括科研
因為,research = 信息處理 + 假設生成 + 驗證。
ai各個部分都比人強,而且還在快速變得更強。
就算真正的天才級別的“靈光一現”比方說廣義相對論的發現,可能是最難被取代的,但這類科研佔比極少。
儘管如此,廣義相對論是不是也相當於人腦裡LLM的極致的泛化?
查看原文包括科研
因為,research = 信息處理 + 假設生成 + 驗證。
ai各個部分都比人強,而且還在快速變得更強。
就算真正的天才級別的“靈光一現”比方說廣義相對論的發現,可能是最難被取代的,但這類科研佔比極少。
儘管如此,廣義相對論是不是也相當於人腦裡LLM的極致的泛化?
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
新紀錄!20萬人口規模城市級別的15年超長期電力合同將帶來哪些影響?
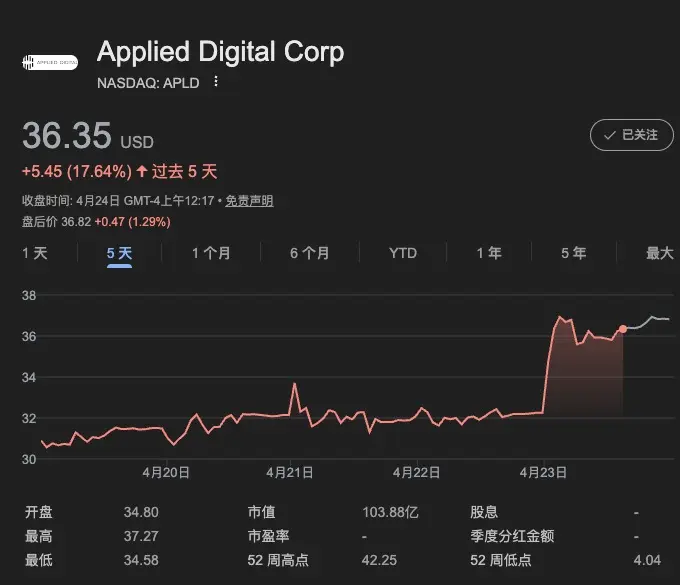
Applied Digital Corporation(apld) 今天宣布與一家美國投資級 hyperscaler 簽下一份 300MW、15年期、總額約75億美元的長約。
股價應聲大漲近20%。
300MW的規模已經接近20萬人口城市級負載,15年的期限明顯超出傳統數據中心合同;而按容量鎖定的模式,也不同於按GPU或按小時計費的算力租賃。
這在“超大規模 + 超長周期 + 明確算力用途”的基礎設施級AI合同上,創了新的紀錄。
這背後對應的是行業屬性的變化。截止目前的數據中心,本質上仍是IT服務,儘管之前有一些長達5年的合同,但擴容仍按需進行,資源可以遷移和替換;
而現在則逐步變成基礎設施資產,開始用類似電力PPA或能源的15年的長期合同的方式鎖定供給。
算力不再是可以隨時採購的資源,而是需要提前規劃、提前佔位的生產能力。
為什麼會發生這種變化,本質原因是資源開始稀缺,和儲存、芯片、光模塊一樣,對hyperscaler來說,如果不提前鎖定,未來可能根本拿不到資源。
在接下來的演進中,電力資產會被重新定價,甚至重新定義。
有電、有接入能力,和高達100–300MW甚至GW級別的電力擴展能力,同時具備網絡連接條件和開發可行性,都將成為新資產定價的屬性。
歸根結底,這一切指向同一個變化:AI競爭正在從模型和算法層,轉
查看原文Applied Digital Corporation(apld) 今天宣布與一家美國投資級 hyperscaler 簽下一份 300MW、15年期、總額約75億美元的長約。
股價應聲大漲近20%。
300MW的規模已經接近20萬人口城市級負載,15年的期限明顯超出傳統數據中心合同;而按容量鎖定的模式,也不同於按GPU或按小時計費的算力租賃。
這在“超大規模 + 超長周期 + 明確算力用途”的基礎設施級AI合同上,創了新的紀錄。
這背後對應的是行業屬性的變化。截止目前的數據中心,本質上仍是IT服務,儘管之前有一些長達5年的合同,但擴容仍按需進行,資源可以遷移和替換;
而現在則逐步變成基礎設施資產,開始用類似電力PPA或能源的15年的長期合同的方式鎖定供給。
算力不再是可以隨時採購的資源,而是需要提前規劃、提前佔位的生產能力。
為什麼會發生這種變化,本質原因是資源開始稀缺,和儲存、芯片、光模塊一樣,對hyperscaler來說,如果不提前鎖定,未來可能根本拿不到資源。
在接下來的演進中,電力資產會被重新定價,甚至重新定義。
有電、有接入能力,和高達100–300MW甚至GW級別的電力擴展能力,同時具備網絡連接條件和開發可行性,都將成為新資產定價的屬性。
歸根結底,這一切指向同一個變化:AI競爭正在從模型和算法層,轉
- 打賞
- 按讚
- 回覆
- 轉發
- 分享
半導體封裝的“隱形中樞”:inline檢測與OSAT的再定價
半導體產業正在經歷一次重心轉移:性能提升不再只依賴晶體管縮小,而是越來越依賴封裝。2.5D、3D、HBM、chiplet,本質上都在把“系統能力”搬到封裝環節。這也直接提高了OSAT(外包封裝與測試)的戰略地位。
封裝重要性的提升,帶來了inline檢測的快速成長。
OSAT(Outsourced Semiconductor Assembly and Test)負責兩件事:
把裸die封裝成可用晶片(封裝)
驗證晶片是否可用(測試)
過去這是一个低技術、低毛利的環節。但在AI時代,情況變了:
多die集成(chiplet)
HBM堆疊
nm級對準要求(hybrid bonding)
封裝正在變成:
性能瓶頸 + 良率瓶頸 + 成本瓶頸
inline是一種生產方式:所有工序連續完成,並在生產過程中實時檢測與反饋(閉環)
對應另一個環節是offline:做完再測(開環)
先進封裝中的inline檢測主要分三類:
1)光學檢測(主力)
bump高度
overlay(對準)
表面缺陷
特點:速度快,可全量inline。
2)X-ray檢測
焊點空洞
TSV缺陷
內部結構問題
特點:能看內部,但速度慢,多用於抽檢。
3)電性測試
功能驗證
性能分檔
更接近最終測試,不屬於核心inline控制體系。
inline檢測的目標不是“最精
查看原文半導體產業正在經歷一次重心轉移:性能提升不再只依賴晶體管縮小,而是越來越依賴封裝。2.5D、3D、HBM、chiplet,本質上都在把“系統能力”搬到封裝環節。這也直接提高了OSAT(外包封裝與測試)的戰略地位。
封裝重要性的提升,帶來了inline檢測的快速成長。
OSAT(Outsourced Semiconductor Assembly and Test)負責兩件事:
把裸die封裝成可用晶片(封裝)
驗證晶片是否可用(測試)
過去這是一个低技術、低毛利的環節。但在AI時代,情況變了:
多die集成(chiplet)
HBM堆疊
nm級對準要求(hybrid bonding)
封裝正在變成:
性能瓶頸 + 良率瓶頸 + 成本瓶頸
inline是一種生產方式:所有工序連續完成,並在生產過程中實時檢測與反饋(閉環)
對應另一個環節是offline:做完再測(開環)
先進封裝中的inline檢測主要分三類:
1)光學檢測(主力)
bump高度
overlay(對準)
表面缺陷
特點:速度快,可全量inline。
2)X-ray檢測
焊點空洞
TSV缺陷
內部結構問題
特點:能看內部,但速度慢,多用於抽檢。
3)電性測試
功能驗證
性能分檔
更接近最終測試,不屬於核心inline控制體系。
inline檢測的目標不是“最精
- 打賞
- 1
- 1
- 轉發
- 分享
ybaser:
只需充電即可完成 👊熱門話題
查看更多16.6萬 熱度
136.94萬 熱度
42.8萬 熱度
1608.88萬 熱度
166.96萬 熱度
已置頂
📢 Gate 廣場 TradFi 交易分享挑戰上線!
晒单瓜分 $30,000 獎池,新人首帖 100% 中獎!
📌 參與方式:
帶 #TradFi交易分享挑战 發帖,滿足以下任一即可:
🔹 帶今日指定 TradFi 幣種標籤發帖交流。
🔹 完成單筆大於 $10U 的 TradFi CFD 交易並掛載交易卡片。
🏷️ 今日指定標籤:USDJPY、AUDUSD、US30、TSLA、JPN225
🎁 寵粉福利:
1️⃣ 卡片分享獎: 抽 50 人,每人送 $100 仓位體驗券!
2️⃣ 發帖榜單獎: 衝排行榜,贏 WCTC 限定 T 恤!
3️⃣ 新粉見面禮: 新人首次發帖,100% 領 $10 體驗券!
詳情:https://www.gate.com/announcements/article/51221🍕 Gate 廣場披薩節正式開啟!
14 年前,有人用 10,000 BTC 買下了兩個披薩。
今天,這兩個披薩已經價值數十億美元。
值此 BTC 披薩日之際,Gate 廣場邀請整個社區一起分享 BTC 故事、Meme、腦洞與交易觀點!
🎁 活動獎勵:
✅ Gate 披薩日周邊禮盒 ×10
✅ 每日 5 份 10 USDT 幸運披薩獎勵
📌 在 Gate 廣場發帖,並同步分享至 X:
Meme、BTC 故事、Pizza 創意圖、BTC 晒單等內容均可參與
立即發布你的 BTC 故事👇
👉️ https://www.gate.com/post
📅 活動時間:5 月 18 日 - 5 月 24 日
詳情:https://www.gate.com/zh/announcements/article/51210
#Gate广场披萨节 #BTC10,000 USDT 悬赏,寻找Gate广场跟单金牌星探!🕵️♀️
挖掘顶级带单员,赢取高额跟单体验金!
立即参与:https://www.gate.com/campaigns/4624
🎁 三大活动,奖金叠满:
1️⃣ 慧眼识英:发帖推荐带单员,分享跟单体验,抽 100 位送 30 USDT!
2️⃣ 强力应援:晒出你的跟单截图,为大神打 Call,抽 120 位送 50 USDT!
3️⃣ 社交达人:同步至 X/Twitter,凭流量赢取 100 USDT!
📍 标签: #跟单金牌星探 #GateCopyTrading
⏰ 限时: 4/22 16:00 - 5/10 16:00 (UTC+8)
详情:https://www.gate.com/announcements/article/50848